義務(wù)教育均衡發(fā)展的重要指標 教學(xué)儀器設(shè)備值洞察與分析
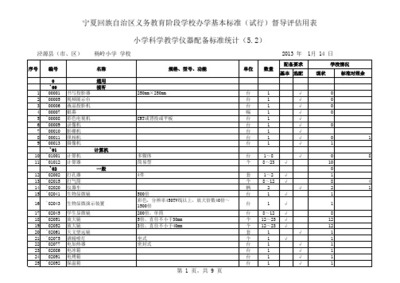
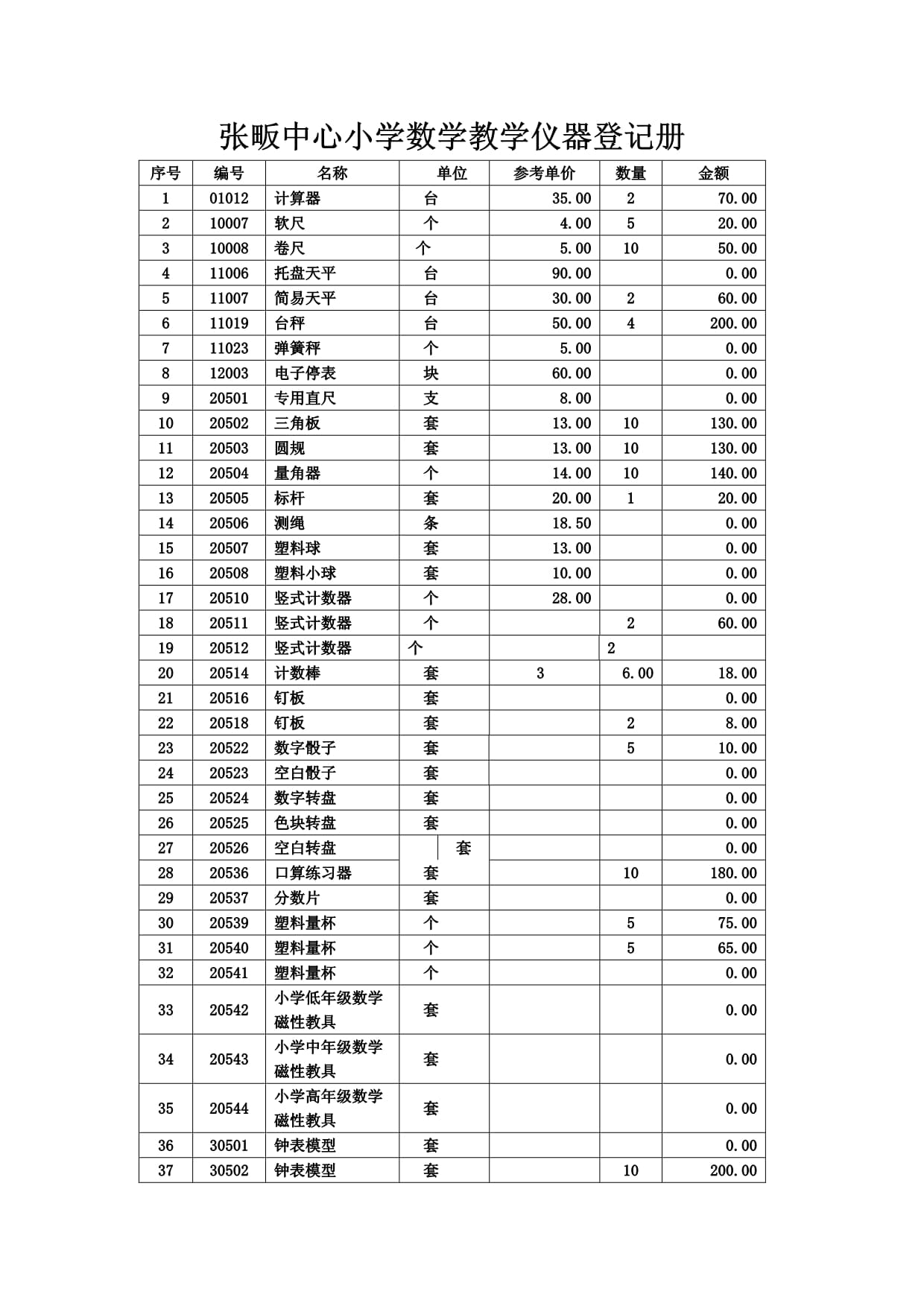
教學(xué)儀器設(shè)備作為現(xiàn)代教育體系中不可或缺的硬件支撐,是提升教學(xué)質(zhì)量、落實課程標準核心要求的關(guān)鍵要素。公開數(shù)據(jù)通常通過《XX市義務(wù)教育階段公辦中小學(xué)教學(xué)儀器設(shè)備值統(tǒng)計表》進行匯總,這筆數(shù)據(jù)直接反映了區(qū)域間教育基礎(chǔ)條件的均衡度。
據(jù)普遍情況顯示,經(jīng)濟發(fā)達城市高于欠發(fā)達地區(qū),但即使在校際之間,‘分值差距’也揭示了資源分配的重大難點。教學(xué)儀器購置的核心矛盾轉(zhuǎn)向設(shè)備運行頻次:某些高價儀器形同“擺設(shè)”,使用率低迷抹掉了統(tǒng)計數(shù)據(jù)上抹額度的優(yōu)勢。分析教學(xué)儀器占用均配模型的誤區(qū)應(yīng)關(guān)注于保養(yǎng)率、損耗與實際消課銜接。如何避免低效投入的嚴峻現(xiàn)象,唯有下沉到各學(xué)校課程所配置的執(zhí)行教具庫考量。強調(diào)機制軟整合方能筑牢條件—— 強底層。這項動態(tài)賬面統(tǒng)計需借鑒多因局束方案通過測量驗收維護臺賬給出科學(xué)跟進依據(jù)校驗消除以優(yōu)差銜接障礙建立終局提救。故表格背后教育邏輯需持續(xù)加大督促區(qū)域優(yōu)質(zhì)通用級儀器共用周轉(zhuǎn)庫建設(shè)促成果基轉(zhuǎn)型夯實均衡基石 。
如若轉(zhuǎn)載,請注明出處:http://m.wlpiyhpjsa.cn/product/16.html
更新時間:2026-06-18 01:27:13